I originally posted this article on the niceRcode blog.
Writing code is fast becoming a key - if not the most important - skill for doing research in the 21st century. As scientists, we live in extraordinary times. The amount of data (information) available to us is increasingly exponentially, allowing for rapid advances in our understanding of the world around us. The amount of information contained in a standard scientific paper also seems to be on the rise. Researchers therefore need to be able to handle ever larger amounts of data to ask novel questions and get papers published. Yet, the standard tools used by many biologists - point and click programs for manipulating data, doing stats and making plots - do not allow us to scale-up our analyses to match data availability, at least not without many, many more ‘clicks’.
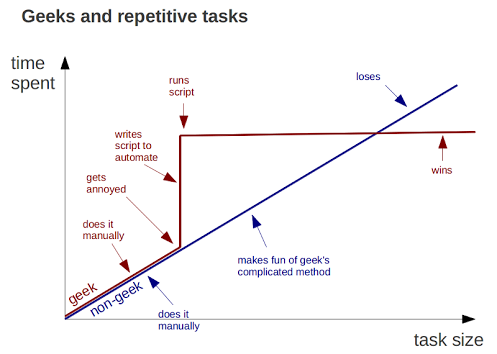
Why writing code saves you time with repetitive tasks, by Bruno Oliveira
The solution is to write scripts in programs like R, python or matlab. Scripting allows you to automate analyses, and therefore scale-up without a big increase in effort.
Writing code also offers other benefits to research. When your analyses are documented in a script, it is easier to pick up a project and start working on it again. You have a record of what you did and why. Chunks of code can also be reused in new projects, saving vast amount of time. Writing code also allows for effective collaboration with people from all over the world. For all these reasons, many researchers are now learning how to write code.
Yet, most researchers have no or limited formal training in computer science, and thus struggle to write nice code (Merali 2010). Most of us are self-taught, having used a mix of books, advice from other amateur coders, internet posts, and lots of trial and error. Soon after have we written our first R script, our hard drives explode with large bodies of barely readable code that we only half understand, that also happens to be full of bugs and is generally difficult to use. Not surprisingly, many researchers find writing code to be a relatively painful process, involving lots of trial and error and, inevitably, frustration.
If this sounds familiar to you, don’t worry, you are not alone. There are many great R resources available, but most show you how to do some fancy trick, e.g. run some complicated statistical test or make a fancy plot. Few people - outside of computer science departments - spend time discussing the qualities of nice code and teaching you good coding habits. Certainly no one is teaching you these skills in your standard biology research department.

Observing how colleagues were struggling with their code, we (Rich FitzJohn and Daniel Falster) have teamed up to bring you the nice R code course and blog. We are targeting researchers who are already using R and want to take their coding to the next level. Our goal is to help you write nicer code.
By ’nicer’ we mean code that is easy to read, easy to write, runs fast, gives reliable results, is easy to reuse in new projects, and is easy to share with collaborators.
We will be focussing on elements of workflow, good coding habits and some tricks, that will help transform your code from messy to nice.
The inspiration for nice R code came in part from attending a boot camp run by Greg Wilson from the software carpentry team. These boot camps aim to help researchers be more productive by teaching them basic computing skills. Unlike other software courses we had attended, the focus in the boot camps was on good programming habits and design. As biologists, we saw a need for more material focussed on R, the language that has come to dominate biological research. We are not experts, but have more experience than many biologists. Hence the nice R code blog.

Key elements of nice R code
We will now briefly consider some of the key principles of writing nice code.
Nice code is easy to read
Programs should be written for people to read, and only incidentally for machines to execute.
— Abelson and Sussman, Structure and Interpretation of Computer Programs
Readability is by far the most important guiding principle for writing nicer code. Anyone (especially you) should be able to pick up any of your projects, understand what the code does and how to run it. Most code written for research purposes is not easy to read.
In our opinion, there are no fixed rules for what nice code should look like. There is just a single test: is it easy to read? To check how nice your code is, pass it to a collaborator, or pick up some code you haven’t used for over a year. Do they (you) understand it?
Below are some general guidelines for making your code more readable. We will explore each of these in more detail here on the blog:
- Use a sensible directory structure for organising project related materials.
- Abstract your code into many small functions with helpful descriptive names
- Use comments, design features, and meaningful variable or function names to capture the intent of your code, i.e. describe what it is meant to do
- Use version control. Of the many reasons for using version control, one is that it archives older versions of your code, permitting you to ruthlessly yet safely delete old files. This helps reduce clutter and improves readability.
- Apply a consistent style, such as that described in the google R style guide.
Nice code is reliable, i.e. bug free
The computer does exactly what you tell it to. If there is a problem in your code, it’s most likely you put it there. How certain are you that your code is error free? More than once I have reached a state of near panic, looking over my code to ensure it is bug free before submitting a final version of a paper for publication. What if I got it wrong?
It is almost impossible to ensure code is bug free, but one can adopt healthy habits that minimise the chance of this occurring:
- Don’t repeat yourself. The less you type, the fewer chances there are for mistakes
- Use test scripts, to compare your code against known cases
- Avoid using global variables, the attach function and other nasties where ownership of data cannot be ensured
- Use version control so that you see what has changed, and easily trace mistakes
- Wherever possible, open your code and project up for review, either by colleagues, during review process, or in repositories such as github.
- The more readable your code is, the less likely it is to contain errors.

Nice code runs quickly and is therefore a pleasure to use
The faster you can make the plot, the more fun you will have.
Code that is slow to run is less fun to use. By slow I mean anything that takes more than a few seconds to run, so impedes analysis. Speed is particularly an issue for people analysing large datasets, or running complex simulations, where code may run for many hours, days, or weeks.
Some effective strategies for making code run faster:
- Abstract your code into functions, so that you can compare different versions
- Use code profiling to identify the main computational bottlenecks and improve them
- Think carefully about algorithm design
- Understand why some operations are intrinsically slower
than others, e.g. why a
forloop is slower than usinglapply - Use multiple processors to increase computing power, either in your own machine or by running your code on a cluster.
The benefits of writing nicer code
There are many benefits of writing nicer code:
- Better science: nice code allows you to handle bigger data sets and has less bugs.
- More fun: spend less time wrestling with R, and more time working with data.
- Become more efficient: Nice code is reusable, sharable, and quicker to run.
- Future employment: You should consider anything you write (open or closed) to be a potential advert to a future employer. Code has impact. Code sharing sites like github now make resumes for you, to capture your impact. Scientists with an analytical bent are often sought-after in the natural sciences.
If you need further motivation, consider this advice
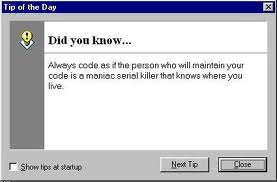
An advisory pop-up for MS Visual C++
This might seem extreme, until you realise that the maniac serial killer is you, and you definitely know where you live.
At some point, you will return to nearly every piece of code you wrote and need to understand it afresh. If it is messy code, you will spend a lot of time going over it to understand what you did, possibly a week, month, year or decade ago. Although you are unlikely get so frustrated as to seek bloody revenge on your former self, you might come close.
The single biggest reason you should write nice code is so that your future self can understand it.
— Greg Wilson, Software carpentry courses
As a by product, code that is easy to read is also easy to reuse in new projects and share with colleagues, including as online supplementary material. Increasingly, journals are requiring code be submitted as part of the review process and these are often published online. Alas, much of the current crop of code is difficult to read. At best, having messy code may reduce the impact of your paper. But you might also get rejected because the reviewer couldn’t understand your code. At worst, some people have had to retract high profile work because of bugs in their code.
It’s time to write some nice R code.
For further inspiration, you may like to check out Greg Wilson’s great article “Best Practices for Scientific Computing.”
Acknowledgements: Many thanks to Greg Wilson, Karthik Ram, Scott Chameberlain and Carl Boettiger and Rich FitzJohn for inspirational chats, code and work.